Publishing Content to Amazon S3
The Amazon S3 connector facilitates publishing deliverable build outputs to the designated bucket.
Requirements
To publish content to an Amazon S3 bucket, you must have the following:
- An AWS account.
- An existing S3 bucket configured. For more details, refer to the AWS S3 Documentation.
- The Access Key ID and Secret Access Key associated with your AWS account. For more details, refer to the AWS Security Credentials Documentation.
For additional information, consult the AWS Documentation.
Define the Connector
- Connector Name
- The name of the connector.
- Region Name
- The AWS Region where your Amazon S3 bucket is hosted. When you create a bucket, you specify the AWS Region where you want Amazon S3 to create the bucket.
- Bucket Name
- The Amazon S3 container used for storing your files.
- Access Key ID
- A unique identifier associated with your AWS account or with an IAM user.
- Secret Access Key
- The secret key used together with Access Key ID for authentication.
Select the Amazon S3 Connector in the Deliverables Page
- After configuring the Amazon S3 connector, navigate to the Deliverables page, then either edit an existing deliverable or create a new one.
- In the resulting configuration page, select the Upload output using a publishing connector option.
- Use the drop-down list below that option to select the Amazon S3 connector that you previously defined.
- Specify the Destination Folder where the build output will be
published. Ensure that the designated folder already exists within the Amazon S3
Bucket.Note: The output will be published as a zip archive in this folder.
- If you want to upload the deliverable's build in ZIP format, select the Upload the deliverable's build output in ZIP format option. By default, it uploads all the build files into the destination folder.
- Click Save at the bottom of the configuration page.
- Begin the Deliverable build process. Upon completion, the build output will be published to the configured Amazon S3 bucket as a zip archive within the folder you specified as the destination folder.
(Optional) Lambda Function to Unzip Content
Prerequisite:
You must have an Amazon role that has S3 Full Access and the AWS Lambda Basic Execution Role policies.

Procedure:
- Go to the AWS Lambda and create a new function.Note: Your Lambda function and the bucket where the documentation is stored should be in the same region.
-
Give your function a name, select the latest version of Python runtime, and your already created role.
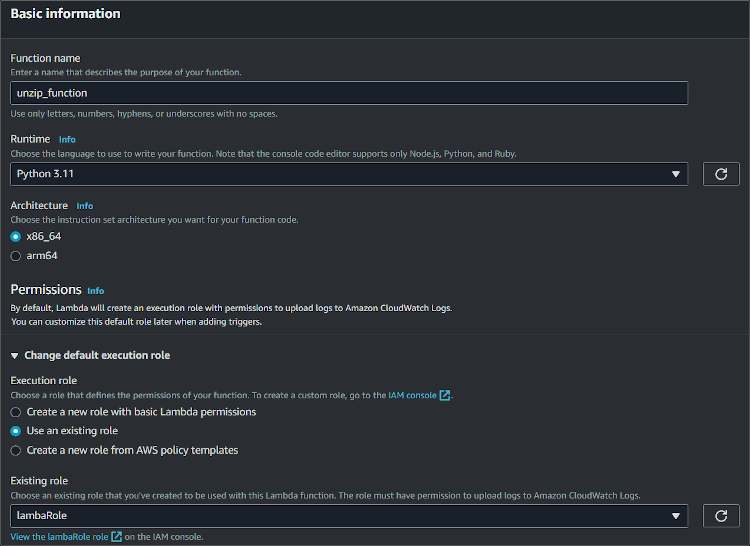
- In the Code section of the function, paste the code into the
lambda_function.py
file.
import zipfile import urllib.parse from io import BytesIO from mimetypes import guess_type import boto3 import logging s3 = boto3.client('s3') logging.getLogger().setLevel(logging.INFO) # Target path to unzip the archive. TARGET_PATH = "target" def lambda_handler(event, context): # Bucket's name. bucket = event['Records'][0]['s3']['bucket']['name'] logging.info("Using bucket: " + bucket); # Zip file's name. zip_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key']) logging.info("File to unzip: " + zip_key); logging.info("Path to unzp the files: " + TARGET_PATH); try: # Get the zipfile from S3 request. obj = s3.get_object(Bucket=bucket, Key=zip_key) z = zipfile.ZipFile(BytesIO(obj['Body'].read())) # Extract and upload each file to the bucket. for filename in z.namelist(): content_type = str(guess_type(filename, strict=False)[0]) s3.upload_fileobj( Fileobj=z.open(filename), Bucket=bucket, Key=TARGET_PATH + filename, ExtraArgs={'ContentType': content_type} ) # Delete the archive after extraction. s3.delete_object(Bucket=bucket, Key=zip_key) except Exception as error: print(f"An error occurred {error=}")Note: If you want to specify a custom target path, then modify the TARGET_PATH variable. For example, if you want to unzip the archive into the Documentation folder, then set the variable to:TARGET_PATH = "Documentation/. - Click the Deploy button to save your changes.
Go to the Configuration tab of the Lambda function.
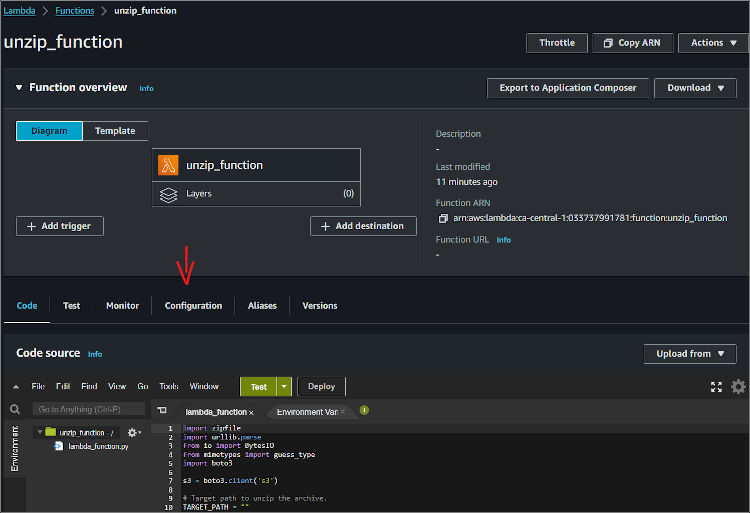
- Click the Edit button of the General Configuration.
- Set the timeout to 15 minutes 0 seconds.Note: If you do not do that, your Lambda function may get timed out and the zip will not be unzipped/deleted.
- Set the Memory to somewhere between 1000-5000 MB.
- Set the Ephemeral storage to somewhere between 1000-5000 MB.Note: If your output's size is bigger than allocated Memory and Ephemeral storage the lambda function may fail to execute.
- Click Save button.
-
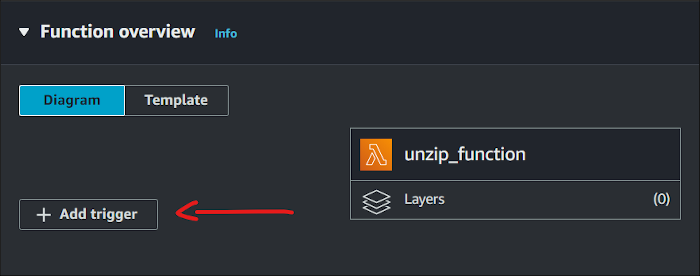
In the Function overview section, click the Add Trigger button.
- As a Source Trigger, select S3.
- Select your desired bucket.
- Select All object create events for Event Types.
-
In the Suffix field, type .zip so that the Lambda function will only trigger for .zip files.
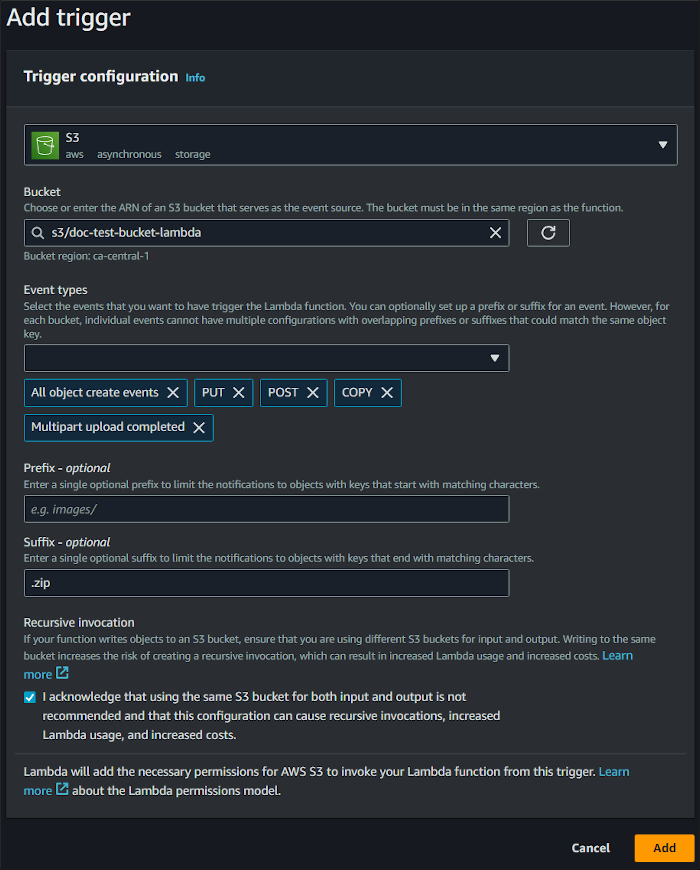
- Click Add.
Result: The AWS Lambda Function should trigger every time a .zip file is uploaded, and it will unzip it and replace the files in the target directory.
(Optional) Lifecycle Rule to Delete Incomplete Uploads
The Amazon S3 connector will use multi-part uploads for larger files to optimize performance. If the upload is interrupted before completion, uploaded parts may remain stored inside your Amazon S3 bucket. It is recommended to configure a Lifecycle Rule for your bucket to automatically delete incomplete multi-part uploads.